PAPS Architecture
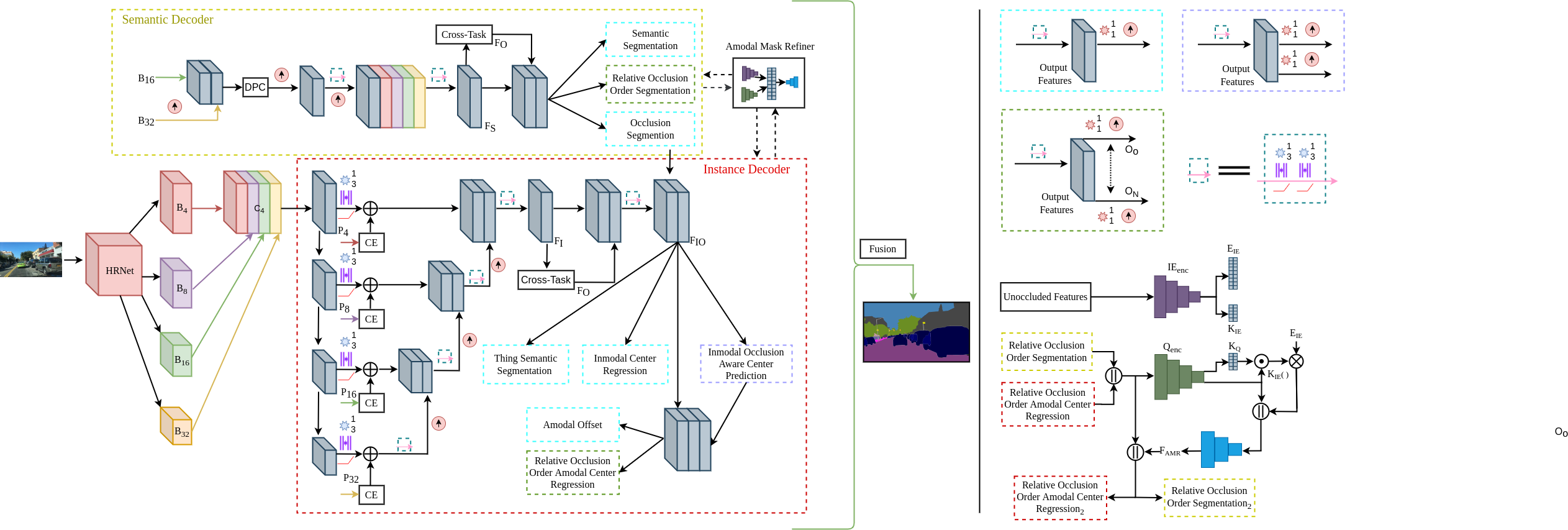
PAPS follows the bottom-up approach. It consists of a shared backbone followed by an asymmetrical dual-decoder consisting of several modules to facilitate within-scale and cross-scale feature aggregations, bilateral feature propagation between decoders, and integration of global instance-level and local pixel-level occlusion reasoning. Further, it incorporates our proposed amodal mask refiner that resolves the ambiguity in complex occlusion scenarios by explicitly leveraging the embedding of unoccluded instance masks. We employ the HRNet architecture as the backbone which specializes in preserving high-resolution information throughout the network. It has four parallel outputs with a scale of ×4, ×8, ×16 and ×32 downsampled with respect to the input, namely, B4, B8, B16, and B32, as shown in Fig. a. We then upsample the feature maps to ×4 and concatenate the representations of all the resolutions resulting in C4, followed by reducing the channels to 256 with a 1 × 1 convolution. Lastly, we aggregate multi-scale features by downsampling high-resolution representations to multiple levels and process each level with a 3 × 3 convolution layer (P4, P8, P16, P32).
The multi-scale representations from the backbone are computed over all four scales which we refer to as cross-scale features. The way these cross-scale features are computed (concatenation, reduction, and downsampling) leads to a limited exploration for multi-scale features at a given individual scale resolution. Since rich multi-scale representations are crucial for the instance decoder’s performance, we seek to enhance the cross-scale features with within-scale contextual features. To do so, we design a lightweight module called the context extractor which is based on the concept of spatial pyramid pooling and is known for efficiently capturing multi-scale contexts from a fixed resolution. We use the context extractor module at each scale (B4, B8, B16, B32) , and add its output to P4, P8, P16, and P32, respectively. The proposed context extractor module employs two 1×1 convolutions, two 3×3 depth-wise atrous separable convolutions with a dilation rate of (1, 6) and (3, 1), respectively, and a global pooling layer. The output of this module consists of 256 channels, where 128 channels are contributed by the 1 × 1 convolution and four 32 channels come from each of the two 3×3 depth-wise atrous separable convolutions and its globally pooled outputs. Further, the sub-tasks, semantic segmentation and amodal instance center regression, are both distinct recognition problems and yet closely related. The intermediate feature representations of each task-specific decoder can capture complementary features that can assist the other decoder to improve its performance. We propose the cross-task module to enable bilateral feature propagation between the decoders to mutually benefit each other. To this end, we fuse the feature inputs from the two decoders adaptively by employing cross-attention followed by self-attention.
The semantic decoder employs three heads, namely, Relative Occlusion Order segmentation, Semantic Segmentation and Occlusion Segmentation. The relative occlusion order segmentation head predicts foreground mask segmentation for ON layers. The masks of each layer are defined as follows: All unoccluded class-agnostic thing object masks belong to layer 0 (O0). Next, layer 1 (O1) comprises amodal masks of any occluded object that are occluded by layer 0 objects but not occluded by any other occluded object. Next, layer 2 (O2) consists of amodal masks of any occluded object, not in the previous layers that are occluded by layer 1 objects but not occluded by any other occluded objects that are not part of previous layers and so on. This separation ensures each thing amodal object segment belongs to a unique layer without any overlaps within that layer. Next, the semantic segmentation head predicts semantic segmentation of both stuff and thing classes. Lastly, the occlusion segmentation head predicts whether a pixel is occluded in the context of thing objects. Lastly, the occlusion segmentation head predicts whether a pixel is occluded in the context of thing objects.
The instance decoder employs a context encoder at each scale (B4, B8, B16, and B32) and adds the resulting feature maps to P4, P8, P16, and P32, respectively. It has five prediction heads. The Inmodal occlusion-aware Center Prediction head consists of two prediction branches, one for predicting the center of mass heatmap of inmodal thing object instances and the other for predicting whether the heatmap is Occluded. Following, the Thing Semantic Segmentation head predicts Nthing+1 classes, where Nthing is the total number of thing semantic classes and the ’+1’ class predicts all stuff classes as a single class. Next, the Inmodal Center Regression head predicts the offset from each pixel location belonging to thing classes to its corresponding inmodal object instance mass center. The remaining heads of the instance decoder are referred to as the Amodal Center Offset and Relative Occlusion Order Amodal Center Regression. The amodal center offset head predicts the offset from each inmodal object instance center to its corresponding amodal object instance center. Whereas, the relative occlusion ordering amodal center regression head, for each relative occlusion ordering layer, predicts the offset from each pixel location belonging to thing classes of the layer to its corresponding amodal object instance mass center. Here, the layers of relative occlusion ordering are defined similarly as in the semantic decoder. Finally, 2e propose the amodal mask refiner module to model the ability of humans to leverage priors on complete physical structures of objects for amodal perception, in addition to visually conditioned occlusion cues. This module builds an embedding that embeds the features of the unoccluded object mask and correlates them with the generated amodal features to complement the lack of visually conditioned occlusion features
Please refer to our paper Perceiving the Invisible: Proposal-Free Amodal Panoptic Segmentation for all the details.