APSNet Architecture
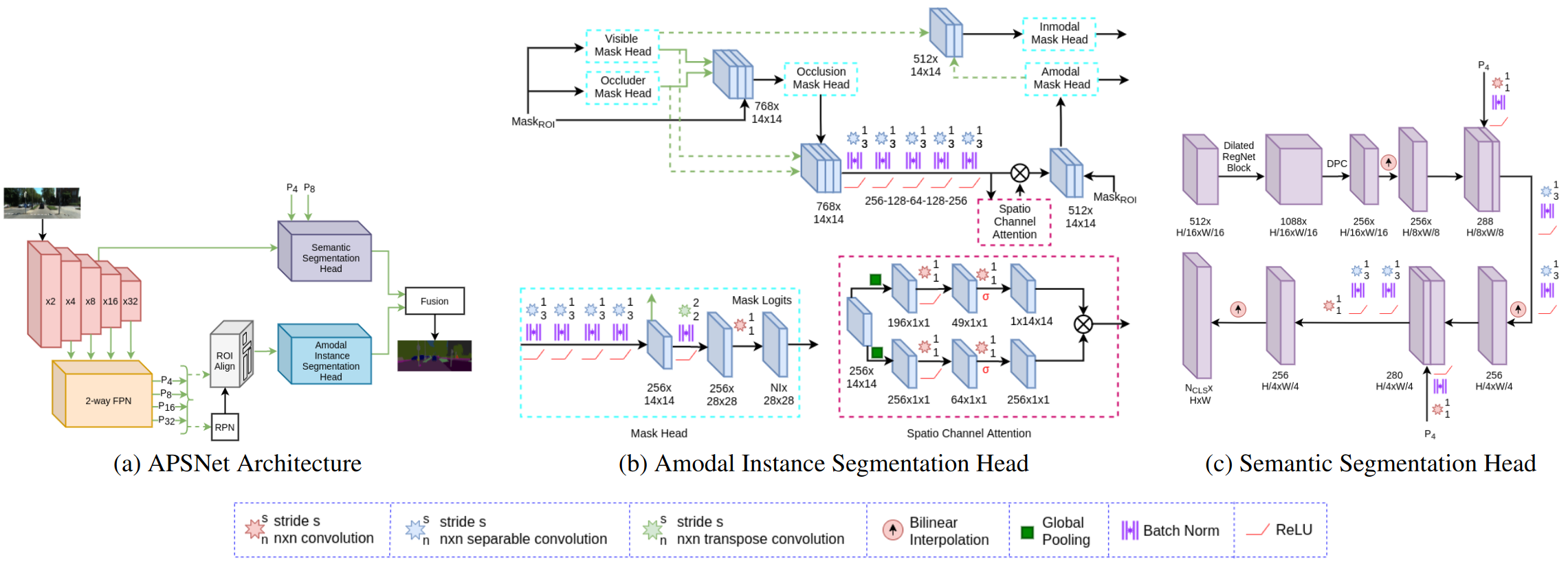
APSNet follows the top-down approach. It consists of a shared backbone that comprises of an encoder and the 2-way Feature Pyramid Network (FPN), followed by the semantic segmentation head and amodal instance segmentation head. We employ the RegNet architecture as the encoder (depicted in red). It consists of a standard residual bottleneck block with group convolutions. The overall architecture of this encoder consists of repeating units of the same block at a given stage and comprises a total of five stages. At the same time, it has fewer parameters in comparison to other encoders but with higher representational capacity. Subsequently, after the 2-way FPN, our network splits into two parallel branches. One of the branches consists of the Region Proposal Network (RPN) and ROI align layers that take the 2-way FPN output as input. The extracted ROI features after the ROI layers are propagated to the amodal instance segmentation head. The second parallel branch consists of the semantic segmentation head that is connected from the fourth stage of the encoder.
Our proposed amodal instance segmentation comprises three parts, each focusing on one of the critical requirements for amodal reasoning. First, the visible mask head learns to predict the visible region of the target object in a class-specific manner. Simultaneously, an occluder head, class-agnostically predicts the regions that occlude the target object. Specifically, the visible mask head learns to segment background objects for a given proposal and the occluder head learns to segment foreground objects. The occluder head provides a global initial guess estimate of where the occluded region of the target object exists. With the features from both visible and occluder mask heads, the amodal instance segmentation head can reason about the presence of the occluded region as well as its shape. This is achieved by employing an occlusion mask head that predicts the occluded region of the target object given the visible and occluder features. Subsequently, the concatenated visible, occluder, and occlusion mask head features are further processed by a series of convolutions followed by a spatio-channel attention block. The aforementioned network layers aim to model the inherent relationship between the visible, occluder and occlusion features. Subsequently, the amodal mask head then predicts the final amodal mask for the target object. Additionally, the visible mask is further refined using a second visible mask head that takes the concatenated amodal features and visible features to predict the final inmodal mask.
The semantic head takes the x16 downsampled feature maps from the stage 4 of the RegNet encoder as input. We employ an identical stage 5 RegNet block with the dilation factor of the 3x3 convolutions set to 2. We refer to this block as the dilated RegNet block. Subsequently, we employ a DPC module to process the output of the dilated block. We then upsample the output to x8 and x4 downsampled factor using bilinear interpolation. After each upsampling stage, we concatenate the output with the corresponding features from the 2-way FPN having the same resolution and employ two 3x3 depth-wise separable convolutions to fuse the concatenated features. Finally, we use a 1x1 convolution to reduce the number of output channels to the number of semantic classes followed by a bilinear interpolation to upsample the output to the input image resolution.
Please refer to our paper Amodal Panoptic Segmentation for all the details.